Agent Explorative Policy Optimization for Multimodal Agentic Reasoning
Minki Kang, Shizhe Diao, Ryo Hachiuma, Sung Ju Hwang, Pavlo Molchanov, Yu-Chiang Frank Wang, Byung-Kwan Lee
Read on arXiv →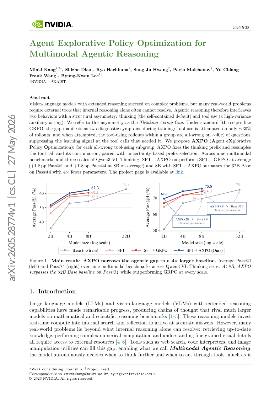
Key claim
AXPO significantly improves tool use in vision-language models.
This paper introduces AXPO, a new approach to improve tool use in vision-language models by addressing the Thinking-Acting Gap. The key result shows that SFT+AXPO outperforms SFT+GRPO across multiple benchmarks, achieving better performance with fewer parameters. This advancement could lead to more effective applications of vision-language models in real-world scenarios.
In plain English
This paper introduces AXPO, a new approach to improve tool use in vision-language models by addressing the Thinking-Acting Gap. The key result shows that SFT+AXPO outperforms SFT+GRPO across multiple benchmarks, achieving better performance with fewer parameters. This advancement could lead to more effective applications of vision-language models in real-world scenarios.
The introduction of AXPO presents a significant new method for addressing the Thinking-Acting Gap in vision-language models.
The claims are supported by multiple benchmarks and a clear comparison to existing methods, though further validation could strengthen the findings.
Deep reliability assessment
The methodology supports the claim that targeted resampling at failed tool-use points improves RL fine-tuning over standard GRPO for Qwen3-VL-Thinking models on the authors' nine multimodal benchmarks. The broader claim that AXPO generally solves the Thinking-Acting Gap is overclaimed without larger-scale models, more tool types, non-verifiable tasks, and external replication.
Reproducibility
No clear open-source code or dataset release is provided in the supplied text; the paper mentions a project page only as 'link'. Evaluation benchmarks and hyperparameters are described, but training data, exact implementation, and repository URL are not available from the excerpt.
Discussion questions
- 1.Does the Thinking-Acting Gap require a new RL algorithm, or could the same gains come from better tool-use SFT data, reward shaping, or higher exploration temperature?
- 2.For builders, is AXPO practical when tool calls are expensive, slow, or involve non-deterministic APIs such as web search, OCR, or enterprise databases?
- 3.What result would falsify AXPO: no gain when controlling for total sampled trajectories, failure on unseen tools, or gains disappearing when evaluated with stricter tool-call correctness metrics?
Key figure
Figure 1 plots average Pass@1 and Pass@4 over nine multimodal benchmarks across Qwen3-VL-Thinking model sizes, showing SFT + AXPO outperforming SFT + GRPO and the 8B AXPO model exceeding the 32B base model on Pass@4.